Summary of Crawling tor
December 08, 2018

Synopsis
The first iteration of the Esper crawler ran successfully for about a week on a single laptop computer. The frontier and seed strategy proved to be useful to gain a high-level perspective. However, only surface-level information was discovered. Due to the requests per-second limitation, only a limited number of pages could be crawled.
Esper
Esper is the 4th generation of my web crawling technology, the current iteration (6th gen) is known as Bandit.
Seed strategy
Extract all .onion domains from the first Google search result page for the query “Hidden Service List”.
Frontier strategy
- [Priority 0] Enumerate through the list of all unique unvisited domains.
- [Priority 1] Enumerate through the list of all unvisited URLs for websites that have a high in-degree value on the hidden service directed graph.
- [Priority 2] Enumerate through the list of all unvisited URLs.
Stats
General
- Initial seed: 352 websites
- Total pages detected 1,233,575
- Total node count: 25,056
- Total Edge count: 100,876
- Total active nodes: 7,323
- Total active edges: 83,14
- Total pages crawled: 28,553
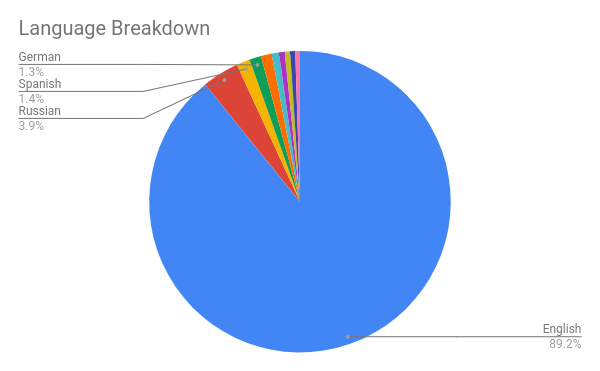
Language
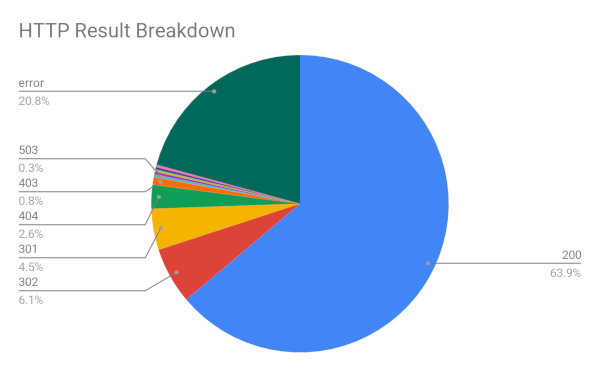
HTTP Responses
Shortcomings/Improvements
-
The fetcher component of the crawler runs at a rate of approximately 1 request/second. This significantly limits the ability to exhaust the entire hidden service directory and URL listing. Significant improvements to the fetcher component must be made in order to adequately gain a more complete picture of the darknet.
-
A target speed of 10 RPS should be achievable with a single network card and CPU.
-
A target speed of 100 RPS should be achievable if cloud services are leveraged.
-
If an adequate picture cannot be extracted with 10 RPS and an appropriate frontier strategy, then Esper will need to be migrated to the cloud.
-
-
A larger seed from more diverse sources should be used to increase the graph size. It is possible that there were self-contained networks that were not found.
- The seed was biased towards English, which may be why the majority of pages crawled were in English.
-
Consider a graph database.
- The domain graph is small enough to run analytics on a single machine.
- If more graph-based analytics continue to be generated, then a graph database would offer significant performance advantages.
-
The frontier strategy has limitations.
- More priority should be given to domains that surfaced from graph-based analytics.
- Deprioritize or blacklist domains with large out-degrees where outbound connections link to nothing.
-
Prioritize large out-degrees that are well connected.
- A number of index sites were not fully enumerated due to frontier limitations. These pages should be prioritized.
-
Deprioritize or blacklist domains with a disproportionate amounts of errors and low in-degree on connected nodes.
- There is no blacklisting mechanism
- Search forms and query strings should be brute-forced if a pattern is easily recognized.
- Deprioritize or blacklist domains within a large localized cluster
- There is no detection of adversarial websites.
- Error count from out-degree should be weighted.
-
The link extractor has limitations.
- Add the illume finite state machine to the link extractor.
-
Graph Visualizations should be built to include the following features
- Language
- Term frequency
Anomalies
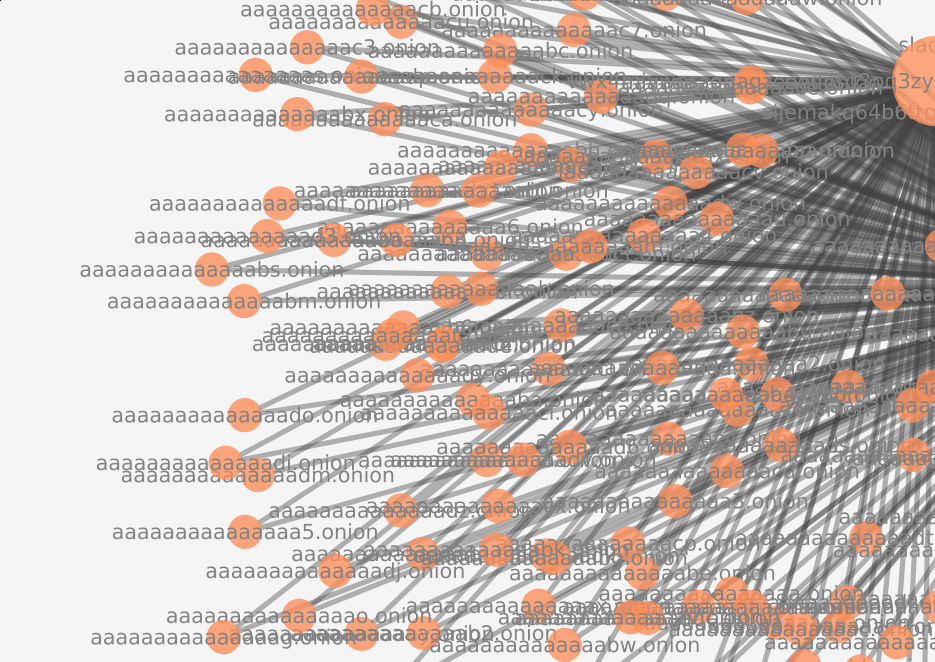
Enumeration of .onion hash space
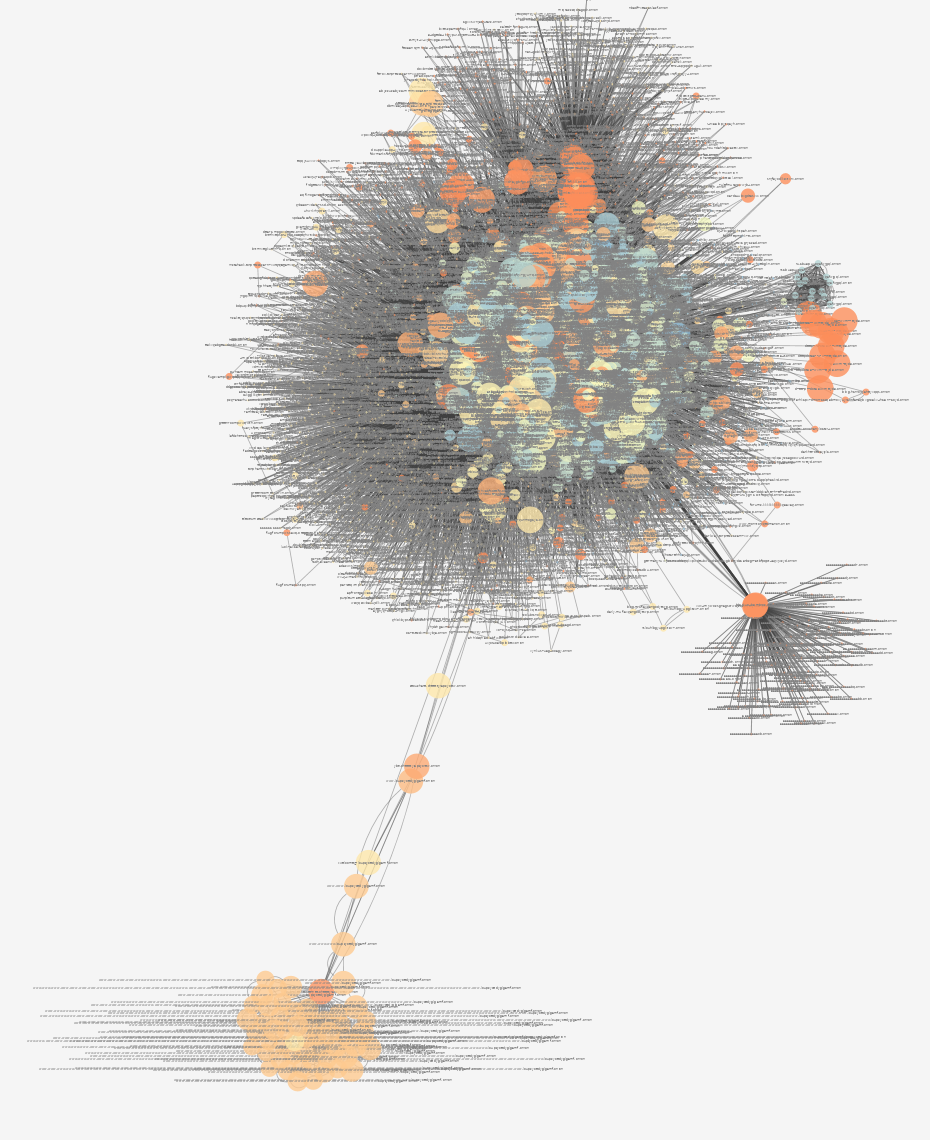
The crawler found a website that enumerated every single domain. Fortunately, the frontier did not prioritize this website, as there were a large number of domains that remained uncrawled. This page was of particular interest, due to the existence of a mirror. This mirror guaranteed that the enumerated websites would have an in-degree of >= 2, which may fool some graph-based frontier strategies.
Anomaly visualized within directed graph
Request by hidden service owner to feed website to web crawlers

Better view of the anomaly within directed graph
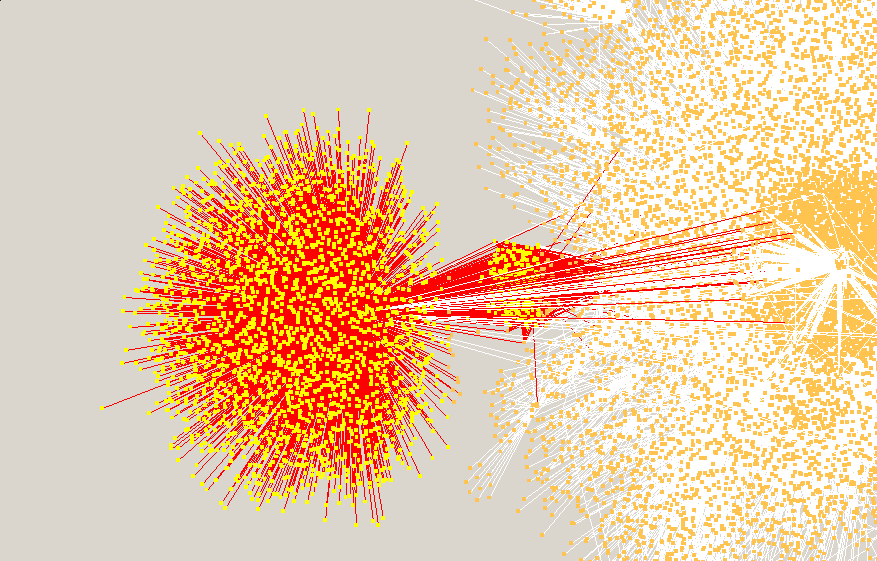
Unconnected segments in the directed graph
Small unconnected network found during initial visualization attempts. The other two nodes to the right later connected with the primary network as the crawl continued.

Potential fraud or law enforcement?

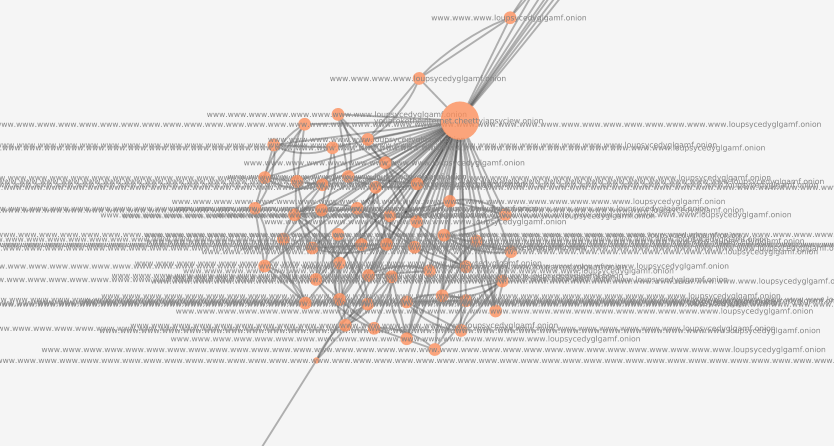
Subdomain enumeration
Adversarial website which uses subdomains to attack the frontier manager, initially thought to be a bug. After discovering this website, the frontier manager was changed to no longer consider a subdomain to be the “primary” unique identifier. The website contains a privacy manifesto not shown on this document.
Full visualization